人工智慧物聯網AIOT文章分享
人工智慧物聯網AIOT-032
先知科技總經理 高季安
September 26, 2024
在上一篇文章中,我們深入探討了機器學習的分類以及監督式學習的應用,透過標籤化的數據讓機器學習如何預測結果。在這篇文章中,我們將把目光轉向兩個不同的學習方式:非監督式學習和增強式學習。這兩者與監督式學習有著很大的不同,它們不依賴於已標籤的數據,卻能解決許多複雜的問題,甚至能自行「摸索」出最優的解決方案。
非監督式學習就像是當你走進一個陌生的房間,沒有人告訴你房間內每個物品的用途,你只能透過觀察與分析來分類和理解。這類學習方式在沒有明確標籤的數據中尋找隱含的模式和結構,特別適合用於資料分群和降維等應用。而增強式學習則更像是一個不斷試錯的過程,透過獎勵和懲罰來學習如何在特定環境中做出最佳決策,就像一個小孩學習如何騎腳踏車一樣,經過多次的嘗試和跌倒,最終掌握平衡的技巧。
接下來,我們將詳細介紹這兩種學習方法,並展示它們如何在日常生活和工業應用中發揮作用。
一、非監督式學習(Unsupervised Learning)
非監督式學習(Unsupervised Learning)與監督式學習最大的不同在於,它不依賴已經標註好結果的數據集。簡單來說,在非監督式學習中,我們有一大堆的輸入資料(X),但並不知道結果(Y)。換句話說,非監督式學習(如圖 1) 沒有明確的答案,也沒有指引你要達到的目標。這樣的學習方式就像是你進入一個陌生的城市,沒有人告訴你每個區域的名字或用途,但你必須透過觀察和分析來區分出不同的區域,進而找出其中的規律。
舉例來說,假設你在分析高雄市的居民資料。你手上只有居民的年齡、收入、教育程度等特徵資料,沒有明確的分類結果(例如,這些居民是否富裕或是他們屬於哪個職業)。這時,你可以使用非監督式學習來找出隱藏在資料中的模式,將相似的居民進行分群。這個過程稱為「分群分析」(Clustering),就像是你把高雄市區分為三民區、甲仙區等地區,雖然你並不知道這些區域內部的具體情況,但可以依據一些特徵將其大致分開。
非監督式學習的應用相當廣泛,尤其在處理大型數據集時,這種學習方式非常有效。常見的應用範圍包括顧客細分、圖像壓縮、資料降維(Dimensionality Reduction)等。顧客細分是一個典型的非監督式學習應用,企業可以根據顧客的購買行為、年齡、性別等特徵進行分群,從而為不同群體量身定做行銷策略。而資料降維則是用來簡化資料的維度,幫助模型更好地進行訓練,提升計算效率。
除了分群之外,非監督式學習的另一個常見應用是「降維」(Dimensionality Reduction)。這個技術主要用於處理高維度的資料,通過壓縮資料,將維度減少到一個更簡單的形式。比如在基因研究中,科學家們會收集成千上萬個基因資料,但並非每一個基因都與研究結果相關。這時,透過降維技術,我們可以找出那些對研究結果最重要的基因,並且在不損失太多資訊的前提下,將資料簡化,以便於進一步的分析。
總的來說,非監督式學習雖然看似沒有一個「正確答案」可以對照,但它卻可以幫助我們在資料中找出隱藏的結構和模式,為後續的決策和應用提供寶貴的資訊。
圖1.人工智慧機器學習分類
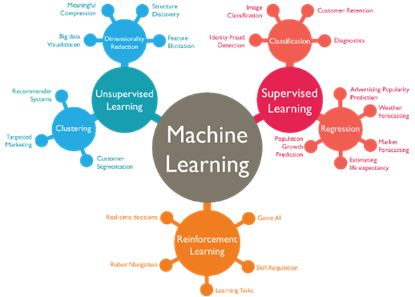
二、增強式學習(Reinforcement Learning)
增強式學習(Reinforcement Learning,簡稱RL)是機器學習中一個非常有趣的分支,它模仿了我們日常生活中學習的許多過程,特別是透過試錯法不斷改進決策的方式。簡單來說,增強式學習的核心概念是透過與環境的互動來獲取反饋(回饋或懲罰),根據這些反饋來調整行為,最終學習到能夠在各種情境中做出最優決策的策略。
我們可以從一個簡單的遊戲例子來理解增強式學習:假設你正在玩一個全新的電玩遊戲,剛開始你對遊戲的規則一無所知,碰到遊戲中的魔王發射炮彈,你可能沒來得及反應就被擊敗了。這時候你學到了第一次教訓:下一次看到炮彈時,你應該要躲避。如果你成功躲過炮彈,你可能會獲得積分獎勵,這就是增強式學習中的「正回饋」——讓你學會在相似的情況下選擇正確的動作。
增強式學習的另一個實例是小孩的學習過程。假設嬰兒在嬰兒床裡哭泣,這可能是因為他餓了或尿布濕了。父母在處理這些問題時,嬰兒很快會學到:當他哭泣時,父母就會來解決他的需求,這樣的行為被強化了。然而,當這個小孩長大後,如果他想要玩具而哭泣,情況可能就不同了。如果父母選擇在這個時候忽視他的哭泣或不給他玩具,那麼小孩會學到,這種行為在這個情境下是不會帶來回報的。這就是增強式學習中的「懲罰機制」——通過減少不當行為來調整未來的決策。
增強式學習與其他學習方式的不同之處在於,它並不是依賴已知的資料或明確的結果(像是監督式學習的X和Y),而是依賴環境中的回饋來學習。在增強式學習的模型中,有幾個重要的元素:
- 代理(Agent):進行決策的主體,例如遊戲中的角色或現實中的機器人。
- 環境(Environment):代理與之互動的世界,會給出回饋。例如,遊戲中的世界或機器人所在的工廠。
- 行為(Action):代理在某一情境下採取的動作,像是選擇躲避炮彈或選擇繼續前進。
- 回饋(Reward):環境根據代理的行為給出的反饋,可能是積分獎勵或懲罰。
舉例來說,增強式學習在自駕車領域中應用廣泛。自駕車不斷地與周遭的環境互動,學習如何在不同的交通狀況下做出最佳的行為選擇。當車輛成功避開障礙物或順利到達目的地時,它會獲得正面的回饋;而當它做出錯誤的決策(例如撞到障礙物),系統會給出懲罰,讓車輛知道下次應該避免這樣的行為。
總結來說,增強式學習的優勢在於它能夠在沒有明確目標的情況下,透過不斷的試錯法找到最優解。這種學習方式在動態、複雜的環境中非常有效,像是機器人導航、遊戲AI、自駕車等應用中都能看到增強式學習的身影。
作者已盡力查證相關資料來源,若是讀者對此系列文章有任何資料來源的指正或其他意見,歡迎提供正確資料來源與建議,請投書: fs-tech@fs-technology.com。
由於篇幅限制,若讀者針對數位轉型(例如人工智慧或物聯網) 相關議題有興趣或想共同進行合作,皆可與先知科技聯絡 (fs-tech@fs-technology.com 或http://www.fs-technology.com/)。
E-mail: fs-tech@fs-technology.com