人工智慧物聯網AIOT文章分享
人工智慧物聯網AIOT-035
先知科技總經理 高季安
October 17, 2024
在前一篇文章中,我們已經深入探討了如何根據不同情境與數據類型來選擇合適的演算法,如同在廚房裡挑選適當的鍋具一樣——煮湯需要湯鍋,煎蛋則少不了平底鍋。而今天,我們要更進一步,帶大家了解 AI 技術實現的不同類型,包含 監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learning)、強化學習(Reinforcement Learning) 與 深度學習(Deep Learning),看看它們如何在我們的日常生活和產業中扮演重要角色。
讓我們想像這些學習方法就像培養不同性格的孩子。監督式學習像是父母耐心指導,告訴孩子「這是貓,那是狗」;非監督式學習則像讓孩子自己探索,從一大堆玩具裡找到最愛的積木;強化學習則像在遊戲中,孩子不斷試錯,學習什麼動作能得到糖果獎勵。至於深度學習,則像是大師級的訓練生,它能模仿人腦的思考方式,從複雜的資料中挖掘出模式和規則,幫助我們解決更高難度的問題。
在這篇文章中,我們將逐一介紹這四種學習方式,並透過生活中的實例,深入淺出地解析它們的應用和差異,讓你輕鬆理解複雜的 AI 技術,不再覺得這些詞彙高深莫測。現在,就讓我們一起進入這場 AI 的學習旅程,探索人工智慧如何透過不同的學習方法改變世界,開創未來的新可能!
一、人工智慧演算法分類-技術實現:
接下來我們將深入探討 人工智慧(AI) 的四大實現技術分類:監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learning)、強化學習(Reinforcement Learning) 與 深度學習(Deep Learning)。這些技術各有特色,且在不同的情境下扮演重要角色,特別是應用於 IoT 和視覺辨識的領域。
圖1.人工智慧演算法分類-技術實現
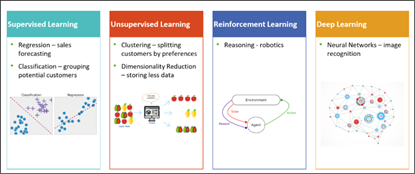
- 監督式學習 (Supervised Learning): 監督式學習的核心在於訓練資料中包含明確的 輸入 X 與輸出 Y 的對應關係。模型在學習過程中,通過大量已知結果的資料來進行學習,直到能夠預測新的輸入資料。這類演算法能解決 預測性任務,但其前提是擁有大量標記的數據。應用案例如:
- 銷售預測(Regression):根據過去的銷售資料,預測未來銷售額。
- 顧客分群(Classification):分類顧客群,如潛在顧客或回購顧客。
- 非監督式學習 (Unsupervised Learning): 與監督式學習不同,非監督式學習沒有標記資料(無 Y)。系統透過自動尋找資料間的結構或模式,進行分類或降維。在 IoT 應用中,這類演算法可幫助企業分析大量感測器資料,找出潛在模式。應用案例如:
- 顧客偏好分群(Clustering):根據消費習慣自動將顧客分群。
- 維度縮減(Dimensionality Reduction):減少資料儲存,方便分析。
- 強化學習 (Reinforcement Learning): 強化學習的核心是「行為與回饋」。系統透過不斷嘗試與環境互動,累積經驗,找出最佳的行動策略。這種技術常用於 遊戲 AI 和 機器人 中。這類學習類似於小朋友在遊戲中學習避開陷阱,經由不斷嘗試錯誤,找出最佳解。應用案例如下:
- 機器人導航:透過學習最佳路徑,避開障礙物。
- 遊戲 AI:如 AlphaGo,不斷學習對戰策略。
- 深度學習 (Deep Learning): 深度學習是機器學習的一個進階分支,特別適用於處理大量資料且無法人工定義特徵的問題。其核心技術是 卷積神經網路(CNN),能自動萃取影像特徵。應用案例如下:
- 影像辨識:如人臉辨識系統,可辨識出是否為校園內合法成員。
- 語音辨識:將語音轉換為文字,提高智能助理的準確度。
二、深度學習與機器學習的比較:
在我們討論人工智慧(AI)應用的過程中,深度學習(Deep Learning) 和 機器學習(Machine Learning) 經常被相提並論。它們雖然都屬於 AI 的一部分,但各自有不同的應用方式和特點。讓我們一起以輕鬆的方式深入了解它們的異同。
圖2.深度學習與機器學習的比較
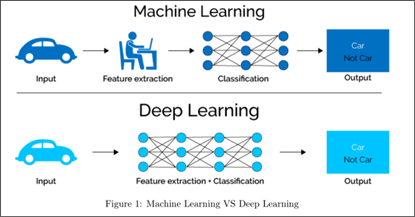
- 機器學習:特徵萃取靠人為,演算法來分類,機器學習的核心在於 人為定義特徵(Feature Engineering),這意味著模型在進行分析前,需要工程師設計出重要的特徵來幫助演算法做出預測。舉例來說,如果我們希望 AI 預測一張圖片中是否有車輛,工程師必須先將圖片中的關鍵特徵(如輪胎的形狀、顏色和大小等)抽取出來,再交給模型進行分類。
- 優勢:機器學習在結構化資料(如表格或統計資料)上表現良好,且模型較為輕量,不需大量運算資源。
- 缺點:需要大量人力參與特徵工程,且效果依賴於工程師對資料的理解。
- 深度學習:特徵自動萃取,適合影像與語音資料,深度學習則是一種進階的技術,透過多層 類神經網路(Neural Network) 自動從資料中學習特徵。當處理高維度資料(如圖片或語音)時,深度學習能直接從原始資料中找出重要的特徵,並進行分類。例如,在影像辨識中,模型會自動分析圖片的像素資訊,並學習如何區分車輛與其他物體。
- 優勢:能處理複雜、高維度的資料,適用於影像辨識、語音轉文字等應用。
- 缺點:需要大量的訓練資料及高性能 GPU 進行運算,且開發成本較高。
- 選擇技術的平衡:速度與精準度之間的取捨,當我們在不同情境下選擇 AI 技術時,需要在 速度 和 精準度 之間做出平衡。
- 若追求速度:如果目標是快速做出決策,例如即時反應系統,建議使用 SVM(支持向量機)或 決策樹,這些演算法能迅速產生結果,且運算資源需求較少。
- 若追求精準度:在需要高度準確的場景中,例如醫學影像分析或語音助理,深度學習的效果會比機器學習更好,但需要更多資源。K-最近鄰演算法(KNN) 和 類神經網路(Neural Networks) 也是適合追求精準度的選擇,但訓練時間可能較長。
- 實務應用中的取捨範例
- 影像辨識系統:如果系統僅需識別簡單物件(如車輛或行人),機器學習即可勝任。但若需辨識複雜影像(如醫療X光片的病灶),則需要深度學習的自動特徵萃取能力。
- 語音助理:日常語音辨識可以利用傳統機器學習演算法處理,但若需要針對大量語音資料進行精準分析,深度學習的卷積神經網路(CNN)表現更優秀。
雖然深度學習提供了強大的自動化能力,但並非所有情境都需要這麼複雜的技術。一般來說,若機器學習演算法已足夠解決問題,就不必使用深度學習,以降低成本與運算資源的消耗。但在處理 非結構化資料(如影像、語音) 或需要高度精準的應用時,深度學習則成為不可或缺的技術。
總而言之,深度學習和機器學習的選擇取決於需求。未來隨著運算能力的提升與演算法的進步,我們將看到越來越多這兩類技術結合應用的案例,不論是政府數位轉型還是日常生活,AI 都將成為我們的重要夥伴。
作者已盡力查證相關資料來源,若是讀者對此系列文章有任何資料來源的指正或其他意見,歡迎提供正確資料來源與建議,請投書: fs-tech@fs-technology.com。
由於篇幅限制,若讀者針對數位轉型(例如人工智慧或物聯網) 相關議題有興趣或想共同進行合作,皆可與先知科技聯絡 (fs-tech@fs-technology.com 或http://www.fs-technology.com/)。
E-mail: fs-tech@fs-technology.com