人工智慧物聯網AIOT文章分享
人工智慧物聯網AIOT-054
先知科技總經理 高季安
March 06, 2025
在上一篇文章中,我們深入探討了人工智慧的類神經網路(Neural Network),並以倒傳遞神經網路(BPNN, Backpropagation Neural Network)為例,說明了輸入層、隱藏層與輸出層的基本運作機制。你可能會想:「這樣就完成 AI 了嗎?」其實,類神經網路只是 AI 學習的一部分,還有許多數據處理層在背後默默支援,確保 AI 能夠發揮真正的智慧。
接下來的文章,我們將以數據 AI(Data-Driven AI)為例,探討在真正的 AI 模型架構中,數據如何影響 AI 的準確度與表現。在訓練神經網路之前,我們需要經過一連串的數據處理層,這些步驟就像是幫助 AI 變得更聰明的「助手」。例如:特徵萃取層(Feature Extraction)、標準化層(Normalization)、關聯層(Correlation Layer)與參數縮減層(Dimensionality Reduction)。
這些數據處理技術就像是 AI 學習前的「暖身運動」,讓 AI 在真正學習之前,能夠掌握最乾淨、最有價值的資訊。接下來,讓我們一起拆解這些關鍵技術,看看 AI 如何透過數據處理,變得更精準、更高效!
一、AI 的學習之路:從數據處理到神經網路的建構
在人工智慧(AI)領域,數據就是燃料,神經網路就是引擎,要讓 AI 順利運作,光有強大的演算法還不夠,數據的處理方式才是影響 AI 學習效果的關鍵因素。
在上一篇文章中,我們介紹了類神經網路(Neural Network)的概念與 BPNN(倒傳遞神經網路)架構,而在這篇文章中,我們要進一步探討 AI 神經網路模型的數據處理流程,以及這些流程如何幫助 AI 學習更準確、更高效。
圖1. 從數據處理到神經網路的建構
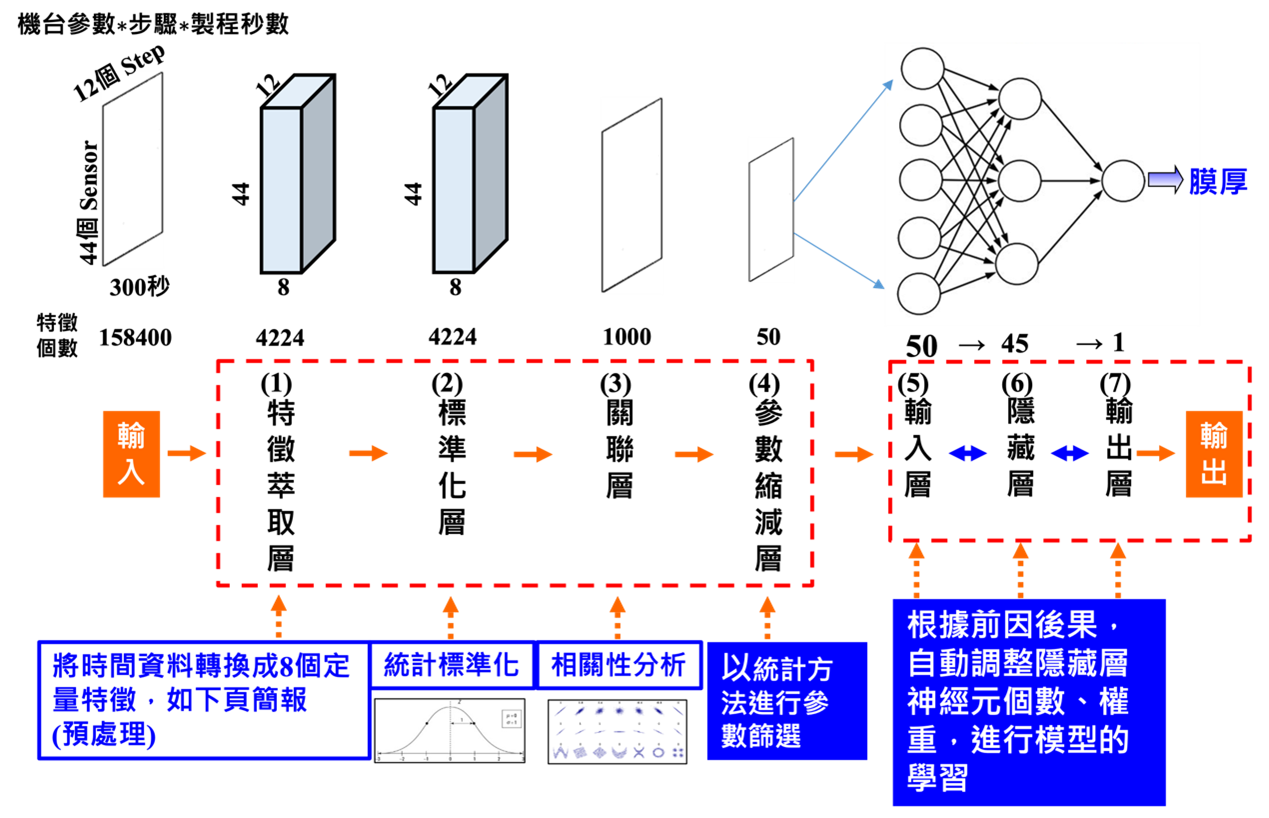
- AI 學習的基本流程
要讓 AI 學習,我們可以將整個過程拆解為幾個主要階段(如圖1):
- 數據蒐集(Data Collection): 取得可用的數據。
- 數據前處理(Data Preprocessing): 清理數據、標準化、去除噪音。
- 特徵萃取(Feature Extraction): 找出關鍵資訊,減少不必要的數據干擾。
- 數據標準化(Normalization): 讓數據符合模型的輸入需求,提高學習效果。
- 關聯分析(Correlation Analysis): 找出數據之間的關係,提高模型預測能力。
- 參數縮減(Dimensionality Reduction): 降低數據的維度,減少計算負擔。
- 神經網路學習(Neural Network Training): 訓練 AI 模型,使其能夠進行預測或決策。
- 模型優化(Model Optimization): 自動調整隱藏層、權重,提升 AI 的學習能力。
這些步驟就像是幫助 AI 進行「資料篩選、整理與理解」的過程,確保 AI 學到的是有價值的資訊,而不是被噪音干擾。
- 各數據處理層的技術解析
在 AI 建模的過程中,數據處理層扮演了「篩選與調整」的重要角色,讓我們來看看這些層的功能與技術。
- 數據前處理(Data Preprocessing)
數據前處理就像是「打掃房間」,把雜亂無章的數據整理好,讓 AI 更容易學習。主要步驟包括:
- 去除異常值(Outlier Removal):刪除不合理的數據點,例如氣溫數據中突然出現 1000 度的錯誤值。
- 處理遺漏值(Missing Data Handling):當數據缺失時,可以用平均值補齊,或透過 AI 預測缺失數據。
- 標準化與正規化(Normalization & Standardization):將不同範圍的數據調整到相同標準,讓 AI 訓練更穩定。
- 應用案例:在製造業中,機台感測器可能會產生一些錯誤數據,例如機台短暫故障時的異常數值,透過前處理可以排除這些錯誤點。
- 特徵萃取(Feature Extraction)
在數據中,並不是所有資訊都對 AI 有幫助,特徵萃取的目的就是從大量數據中挑選出「最具代表性」的資訊。
- 時間序列分析(Time Series Analysis):分析數據的變化趨勢,例如工業生產線的機器振動數據。
- 影像特徵萃取(Image Feature Extraction):從影像中提取邊緣、紋理、顏色等特徵,幫助 AI 進行影像分類。
- 關鍵變數選擇(Key Variable Selection):在多維度數據中挑選影響 AI 預測結果最重要的變數。
- 應用案例:在半導體製造中,影響晶圓品質的參數可能有數百種,特徵萃取可以幫助找到最關鍵的 5~10 個參數,提升 AI 預測能力。
- 數據標準化(Normalization)
標準化數據的目的是讓不同單位的數據變得「有可比性」。
- Z-score 標準化(減去均值再除以標準差)。
- Min-Max 正規化(將數據縮放到 0~1 之間)。
- 應用案例:在 AI 進行金融風險評估時,信用分數(0~1000)和收入(數百萬美元)數值範圍不同,透過標準化可以讓 AI 更容易學習這些數據之間的關係。
- 關聯層(Correlation Layer)
這一層的作用是找出數據之間的相關性,幫助 AI 更準確地做出判斷。例如:
- 機器運行溫度與故障率的關係。
- 生產線速度與產品不良率的關聯性。
- 應用案例:在智慧製造中,關聯層可以幫助分析「產線溫度變化是否會影響良率」,找到影響產品品質的關鍵因素。
- 參數縮減層(Dimensionality Reduction)
當數據維度過多時,AI 會變得「負擔過重」,影響學習效率,因此我們需要「壓縮數據維度」,去除不必要的數據點。
- PCA(主成分分析):透過統計方法,找出最重要的數據組合。
- LDA(線性判別分析):根據標籤來挑選最能區分不同類別的特徵。
- 應用案例:在 AI 預測疾病時,醫院可能會收集大量數據(血壓、血糖、基因資訊等),但 AI 不需要所有數據,因此可以透過參數縮減,挑選最具影響力的幾個變數來進行分析。
- 數據前處理(Data Preprocessing)
- AI 如何根據數據學習?
當 AI 完成數據處理後,神經網路會開始進行學習,並透過權重調整(Weight Adjustment)來逐步改善預測準確度。AI 會反覆計算輸入數據的影響,調整隱藏層的神經元數量、權重,讓模型更接近真實世界的結果。
應用案例:在 AI 預測機器維修需求時,AI 會分析歷史數據並不斷修正權重,讓預測越來越準確。
數據處理是 AI 成功的關鍵,透過數據前處理、特徵萃取、標準化、關聯分析與參數縮減,我們可以讓 AI 更精準、更高效地學習,應用於製造業、醫療、金融等領域。這些技術不僅提升 AI 的學習效果,也讓 AI 更加貼近人類的需求。
作者已盡力查證相關資料來源,若是讀者對此系列文章有任何資料來源的指正或其他意見,歡迎提供正確資料來源與建議,請投書: fs-tech@fs-technology.com。
由於篇幅限制,若讀者針對數位轉型(例如人工智慧或物聯網) 相關議題有興趣或想共同進行合作,皆可與先知科技聯絡 (fs-tech@fs-technology.com 或http://www.fs-technology.com/)。
E-mail: fs-tech@fs-technology.com